Appearance

Résumé exécutif : Dans une organisation polycéphale, la Gouvernance des Données est un défi complexe. Cet article explore la mise en œuvre d'une Plateforme de Données basée sur Dagster pour la Fédération Wallonie-Bruxelles (FWB). Il met en évidence l'importance de l'automatisation, de la modularité et de la réutilisabilité des composants pour abaisser la barrière technique et améliorer la littératie des données parmi les analystes de données et les gestionnaires de données.
Les opinions exprimées sur ce site web sont les miennes et ne reflètent pas nécessairement celles de mon employeur.
Table des matières
🏛️ Contexte
La Communauté française de Belgique (ou Fédération Wallonie-Bruxelles, FWB) désigne l'une des trois communautés linguistiques constitutionnelles de Belgique.
La Communauté française de Belgique comprend ~4,5 millions de personnes et son administration est responsable de la gestion de l'enseignement, de la culture, du sport, de l'aide à la jeunesse, des relations internationales, etc. pour la population francophone du pays. L'administration elle-même emploie plus de 7 000 personnes, mais le nombre d'employés du secteur public qui dépendent directement de la FWB est beaucoup plus élevé, principalement en raison des secteurs de l'enseignement et de la garde d'enfants.
Le Ministère de la FWB (MFWB) est une organisation complexe avec plusieurs entités appelées "Administrations générales" (ou AG). Chacune de ces entités gère ses propres données — souvent en silos — et possède ses propres structures de gouvernance composées de diverses couches de Services et Directions avec des Chefs de projet, des Product Owners, des Analystes métier, etc. Sous cette complexité organisationnelle, le paysage technique est bien sûr également complexe. Chaque AG a ses propres produits, applications, SGBD, DWH, outils BI, etc. Cela conduit à un manque de cohérence et de qualité dans les données. Les employés utilisent principalement des produits Microsoft (Excel) pour leurs besoins en gestion et analyse de données. Très peu de personnes sont formées à la gestion des données et à la programmation, ce qui conduit parfois à un manque de compréhension de l'importance de la gouvernance des données.
La nature polycéphale de l'organisation rend difficile la gouvernance et la mise en œuvre d'une plateforme de données unifiée répondant aux besoins de toutes les parties prenantes.
🎯 Quelle est notre stratégie de données ?
La stratégie de données de la Communauté française de Belgique (FWB), connue sous le nom de "Données au Centre", est en place depuis 2020 et vise à améliorer la gestion et l'exploitation des données pour améliorer la prestation de services et la gouvernance.
Les éléments clés de la stratégie incluent :
- Attribuer un Data Owner et un Data Steward à chaque ensemble de données significatif pour assurer la responsabilité et une gestion appropriée.
- Fournir un accès brut aux ensembles de données pour le personnel autorisé, tout en respectant les exigences de conformité légale obligatoires.
- Offrir une formation technique et non technique aux Data Owners et Data Stewards sur des sujets tels que les indicateurs de données, la visualisation, la gouvernance, Python et SQL pour améliorer leurs compétences en gestion de données.
- Cultiver une culture centrée sur les données (Données au centre) grâce à une documentation complète, une formation et des réunions communautaires régulières pour encourager l'utilisation efficace des ressources de données.
La stratégie décrit des objectifs axés sur l'amélioration de la qualité, de la disponibilité et de la sécurité des données, et sur la promotion de la collaboration au-delà des frontières organisationnelles. Elle cherche à identifier les actifs de données stratégiques cruciaux pour les opérations du ministère, à développer des tableaux de bord stratégiques et opérationnels pour une prise de décision éclairée, et à promouvoir le partage et la réutilisation des données au-delà des barrières organisationnelles.
De plus, la stratégie priorise la conformité RGPD pour les données personnelles, l'intégration des données de référence dans les solutions métier, et la publication des données via la plateforme Open Data pour améliorer la transparence et l'accessibilité.
📦 Où sont les données ?
Dans le contexte de ce type d'organisation, les données brutes sont collectées à partir de diverses sources, notamment des bases de données, des API et des fichiers plats. La nature hétérogène de ces sources rend difficile la garantie de l'accès aux données, de leur qualité, de leur cohérence — et donc de leur exploitation. Pour relever ce défi, une décision prise il y a des années a été de mettre en œuvre une couche de virtualisation (basée sur Denodo) au-dessus des SGBD.
Denodo est un outil puissant pour la virtualisation des données, mais il nécessite un certain niveau d'expertise pour la configuration et la maintenance. Cela peut être un obstacle pour certaines équipes, en particulier celles disposant de ressources techniques limitées. Il n'est pas non plus 100% conforme à la plupart des standards SQL (Denodo VQL), ce qui peut entraîner de la confusion et des erreurs lors du travail avec les données (à travers les systèmes en amont et en aval).

🏗️ Quelle est notre pile de données ?
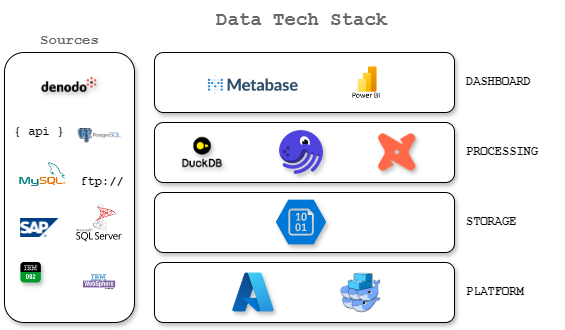
Une pile de données est généralement composée de plusieurs composants qui fonctionnent ensemble pour gérer et traiter les données. Les composants spécifiques d'une pile de données peuvent varier en fonction des besoins de l'organisation, mais ils incluent généralement :
- Sources : Ce sont les systèmes et applications qui génèrent et stockent des données. Ils peuvent inclure des bases de données, des API, des fichiers plats et d'autres référentiels de données.
- Plateforme : C'est là que le calcul est effectué pour traiter et analyser les données. Elle peut inclure des plateformes basées sur le cloud, des serveurs sur site et d'autres ressources informatiques.
- Stockage : C'est là que les données sont stockées pour une utilisation ultérieure. Il peut inclure des bases de données, des lacs de données et d'autres solutions de stockage.
- Traitement : C'est là que les données sont transformées et préparées pour l'analyse. Il peut inclure des processus ETL (Extract, Transform, Load), des pipelines de données et d'autres outils de traitement de données. Cela inclut également les processus ML et AI qui peuvent être utilisés pour analyser et extraire des insights des données.
- Tableau de bord : C'est là que les données sont présentées d'une manière facile à comprendre et à analyser. Il peut inclure des tableaux de bord, des rapports et d'autres outils de visualisation.
Notre pile de données comprend actuellement plusieurs composants :
Nous avons également essayé plusieurs outils avant de nous arrêter sur ce que nous avons aujourd'hui. L'objectif était de trouver une solution qui soit flexible, auditable, transparente et évolutive. Par "auditable", nous entendons un système où chaque action et modification peut être suivie, enregistrée et examinée pour garantir la responsabilité et la conformité.
Nous voulions également éviter le vendor lock-in 🔒 et nous assurer que la solution pourrait être adaptée aux besoins de l'organisation et au niveau d'expertise technique des utilisateurs.
Sur la base de ces exigences, en termes d'orchestrateurs, nous avons essayé Airflow pendant quelques semaines et nous nous sommes appuyés sur Prefect pendant quelques mois. Nous avons ensuite décidé de passer à Dagster, pour un ensemble de raisons :
- Fonctionnalités d'observabilité des données au cœur de l'architecture -- c'est une exigence clé pour nous ;
- Séparation de l'emplacement du code pour correspondre à la nature fortement décentralisée de la FWB ;
- Grande communauté et documentation qualitative unifiée ;
La nouvelle architecture comprend une plateforme de données qui s'intègre aux sources de données et outils existants, offrant une approche plus rationalisée et efficace de la gestion des données.
Sur la base de notre contexte et de nos choix, la mise en œuvre d'un orchestrateur de données réussi pour la FWB repose sur deux défis clés : l'onboarding facile et la littératie des données de nos utilisateurs. Pour y parvenir, nous devons nous concentrer sur les aspects suivants :
🤖 Automatiser tout (ou presque) : faciliter l'intégration
Développer un logiciel comme une plateforme de données est une tâche complexe qui nécessite beaucoup de temps et d'efforts. Pour faciliter l'intégration et l'utilisation de la plateforme par les utilisateurs, nous devons nous concentrer sur l'automatisation du processus autant que possible. Voici un aperçu de notre stratégie d'automatisation :
- Automatiser les tests : Mise en œuvre de tests complets, des tests unitaires aux tests d'intégration
- Automatiser le déploiement : Pipeline de déploiement multi-environnement (test, staging, production)
- Automatiser l'intégration : Connexion transparente avec les systèmes existants de la FWB
- Automatiser la surveillance : Surveillance proactive du pipeline et de la qualité des données
💡 Pour une plongée détaillée dans notre implémentation de l'automatisation, y compris les configurations GitLab CI/CD et des exemples d'assets Dagster, consultez la partie 2 de cette série.
📚 Littératie des données : Abaisser la barrière et donner du pouvoir aux utilisateurs
Comme la plupart de nos utilisateurs ne sont pas des professionnels de la donnée formés, nous avons développé plusieurs stratégies pour rendre la plateforme plus accessible :
- Réduction de la barrière technique : Interfaces et workflows conviviaux
- Développement de ressources de base : Composants et modèles réutilisables
- Cadre de bonnes pratiques : Normes claires pour le codage, les tests et le déploiement
- Intégration de l'IA : Tirer parti de l'IA pour l'assistance au développement de pipelines
- Architecture de code modulaire : Emplacements de code indépendants pour une complexité réduite
💡 Dans la partie 3 de cette série, nous explorerons comment nos ressources personnalisées ont amélioré la gouvernance des données et rendu la plateforme plus accessible aux utilisateurs de tous les niveaux techniques.