Appearance

Résumé exécutif : Dans une organisation polycéphale, la Gouvernance des Données est un défi complexe. Cet article explore la mise en œuvre d'une Plateforme de Données basée sur Dagster pour la Fédération Wallonie-Bruxelles (FWB). Il met en évidence l'importance de l'automatisation, de la modularité et de la réutilisabilité des composants pour abaisser la barrière technique et améliorer la littératie des données parmi les analystes de données et les gestionnaires de données.
Les opinions exprimées sur ce site web sont les miennes et ne reflètent pas nécessairement celles de mon employeur.
Table des matières
Si vous souhaitez encourager les analystes de données et les gestionnaires de données à participer au développement de pipelines de données, vous devez vous assurer que chaque commit est testé et validé avant d'être déployé en production. Vous voulez également automatiser les tâches répétitives pour réduire la barrière technique autant que possible. De plus, vous voulez mettre en place un système d'observabilité solide pour surveiller la santé de vos systèmes et pipelines de données et détecter les problèmes rapidement.
Pour expliquer comment nous automatisons le déploiement des pipelines de données, je vais d'abord décrire l'architecture de notre plateforme de données.
🏗️ Architecture technique de notre plateforme de données
Notre pile est actuellement basée sur les composants suivants :
- Dagster : L'orchestrateur de nos pipelines de données. Il nous permet de définir, planifier et surveiller nos workflows de données.
- dbt-core : L'outil de transformation de données qui nous permet de définir nos modèles et transformations de données de manière modulaire. Il est utilisé pour construire les modèles et transformations de données qui sont exécutés par Dagster.
- DuckDB : Le moteur SQL qui nous permet d'exécuter des requêtes SQL sur nos données. Il est utilisé pour le développement et les tests locaux de nos pipelines de données.
- Azure : Le fournisseur cloud qui héberge notre plateforme de données. Nous utilisons Azure Data Lake Storage (ADLS) pour le stockage des données.
- Docker : La technologie de conteneurisation qui nous permet d'empaqueter nos pipelines de données et leurs dépendances de manière portable.
- GitLab : Le système de contrôle de version qui nous permet de gérer nos dépôts de code et d'automatiser nos pipelines CI/CD.
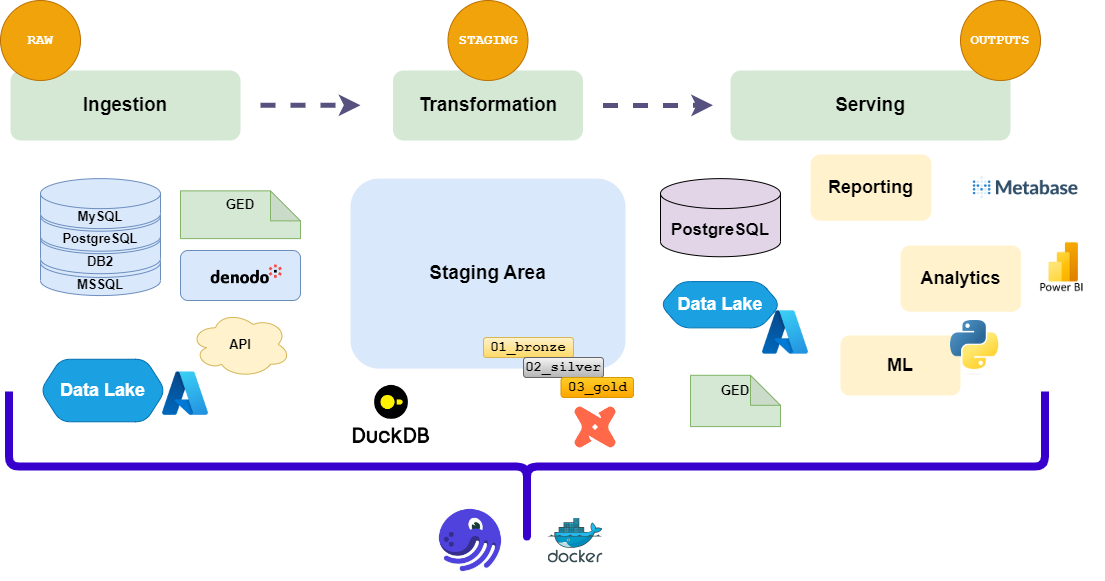
Flux de données dans notre pile
Une remarque importante ici : nos choix techniques ne sont pas gravés dans le marbre. Nous évaluons constamment de nouvelles technologies et approches pour améliorer notre plateforme de données. L'objectif est de fournir une architecture flexible et évolutive qui peut s'adapter aux besoins changeants de l'organisation. Si dbt-core, Dagster, ou tout autre outil/fournisseur ne répond plus à nos besoins, nous n'hésiterons pas à le changer. Ce à quoi nous nous engageons vraiment, c'est l'(1) architecture, et les (2) langages que nous utilisons pour l'implémenter (Python, SQL). Les outils et fournisseurs ne sont que des moyens pour atteindre un objectif.
Pour d'excellentes recommandations sur la façon de construire une plateforme de données solide, je recommande de lire Fundamentals of Data Engineering de Joe Reis et Matt Housley.
Structure des emplacements de code
Pour permettre à chaque administration générale (AG) de posséder son propre dépôt (un code location dans le vocabulaire Dagster)—qui contient l'emplacement de code Dagster pour les pipelines de données de cette AG—nous avons décidé de refléter la structure organisationnelle de la FWB dans l'architecture de notre plateforme de données. Nous utilisons également des emplacements de code distincts pour des projets spécifiques qui ne sont pas liés à une AG spécifique. Cela permet à chaque AG de gérer ses propres pipelines de données de manière indépendante et d'avoir une propriété claire du code. Les emplacements de code sont ensuite agrégés dans une seule instance Dagster, qui est la plateforme de données.
🗂️ Structure de notre dossier d'emplacements de code
bash
dagster_home (main) $ tree -L 1
.
├── ags_project
├── agaj_project
...
├── data_platform # notre emplacement de code générique
├── dagster.yaml
└── workspace.yaml🤖 Automatiser le CI/CD
Flux CI/CD
Notre configuration de déploiement est basée sur les pipelines GitLab CI/CD. Le flux est le suivant :
- Intégration des sous-modules : Les projets DBT sont intégrés comme un sous-module Git dans le dépôt principal. Cela nous permet d'inclure le travail des gestionnaires de données et des analystes dans la plateforme de données sans avoir à dupliquer le code ou à maintenir des dépôts séparés.
- Build : Le code est construit et empaqueté dans une image Docker ; la même image est utilisée pour le Webserver, le Daemon et les emplacements de code.
- Valider les définitions : Les définitions Dagster sont validées pour s'assurer qu'elles sont correctes et ne contiennent aucune erreur.
- Ruff : Le code est vérifié pour les problèmes de style et de formatage à l'aide de Ruff.
- Sonar : Le code est analysé pour les problèmes de qualité et de sécurité à l'aide de SonarQube.
- Test : Le code est testé à l'aide de pytest pour les tests unitaires, les tests d'intégration et l'analyse de couverture.
- Déployer en DEV : Le code est déployé dans l'environnement de développement pour chaque commit dans la branche principale ou une branche de fonctionnalité.
- Déployer en STAGING : Lorsqu'un tag est créé, le code est déployé dans l'environnement de staging.
- Déployer en PROD : Le code est déployé dans l'environnement de production après validation manuelle en staging.
Étapes CI/CD de notre plateforme de données
yaml
# .gitlab-ci.yml (simplifié)
build:
stage: build
script:
- docker compose build
validate:
stage: test
script:
- dagster definitions validate -m data_platform
test:
stage: test
script:
- pytest -v
--cov=. --cov-branch --cov-report=html --cov-report=term
--cov-report xml:coverage.xml
--junitxml=report.xml
ruff:
stage: test
script:
- ruff check --output-format=gitlab .
sonarqube-check:
stage: test
script:
- sonar-scanner
deploy_dev:
stage: deploy
only:
- main
script:
- docker compose up -d
deploy_staging:
stage: deploy
only:
- tags
script:
- docker compose up -d
deploy_prod:
stage: deploy
when: manual
only:
- tags
script:
- docker compose up -dSpécificités des environnements
Les environnements sont configurés dans le fichier docker-compose.yml à l'aide de variables d'environnement. Chaque environnement a ses propres variables d'environnement, qui sont utilisées pour configurer le comportement de la plateforme de données.
Nous utilisons un seul fichier docker-compose.yml dont le contenu peut être adapté en fonction de l'environnement. Le fichier compose contient tous les services nécessaires pour exécuter la plateforme de données, y compris le webserver Dagster, le daemon Dagster et les emplacements de code Dagster.
Dans l'exemple suivant, nous montrons comment nous utilisons le même fichier compose pour déployer la plateforme de données dans différents environnements en utilisant uniquement des variables d'environnement :
yaml
# docker-compose.yml (simplifié)
version: "3.8"
services:
dagster_webserver:
build:
context: .
image: ${DOCKER_IMAGE}:${CI_COMMIT_SHORT_SHA}
restart: unless-stopped
env_file: .env
environment:
- ENVIRONMENT=${ENVIRONMENT} # staging, prod🤖 Automatiser les tests
Tous nos tests sont implémentés en Python à l'aide de pytest. Nous couvrons les tests unitaires, les tests d'intégration et l'analyse de couverture. Cependant, nous testons généralement seulement les parties critiques de notre code, telles que les définitions Dagster, les ressources personnalisées, le code Python et le parsing DBT. Nous ne testons généralement pas les requêtes SQL à moins qu'elles ne contiennent une logique complexe.
🚀 Automatiser le déploiement
Cycle de déploiement de notre plateforme de données
Le cycle de déploiement de notre plateforme de données consiste en les étapes suivantes :
- Développement local → un développeur travaille sur une nouvelle fonctionnalité dans son environnement local.
- Commit → le développeur valide ses modifications dans la branche principale ou une branche de fonctionnalité.
- Build → GitLab CI/CD construit le code et l'empaquette dans une image Docker.
- Test → GitLab CI/CD exécute les tests et génère un rapport de couverture.
- Déployer en DEV → GitLab CI/CD déploie le code dans l'environnement de développement.
- Tag de version → lorsque le développeur est satisfait des modifications, il crée un tag de version.
- Déployer en STAGING → GitLab CI/CD déploie le code dans l'environnement de staging.
- Déployer en PROD → Après validation en staging, GitLab CI/CD déploie le code dans l'environnement de production.

Cycle de déploiement de l'emplacement de code Dagster
Cycle de déploiement de nos projets DBT
Lorsqu'une nouvelle version est créée, le projet DBT est automatiquement versionné à l'aide de l'outil release. La version est incrémentée et un changelog est généré. Le projet DBT est ensuite analysé à l'aide de dbt parse pour produire le fichier manifest.json, qui contient les métadonnées du projet DBT. Ce fichier est utilisé par Dagster pour découvrir les modèles DBT et leurs dépendances.
Le cycle de version de nos projets DBT consiste en les étapes suivantes :
yaml
# .gitlab-ci.yml
sqlfluff:
allow_failure: true
script:
- sqlfluff lint models
release:
script:
- VERSION=$(release next-version)
- |
sed -i "s/version: \"[^\"]*\"/version: \"$VERSION\"/" "$FILETOCHANGE"
- release changelog
- release commit-and-tag --create-tag-pipeline CHANGELOG.md ${DBT_PATH}/dbt_project.yml // [!code focus]
dagster_submodule:
rules:
- if: "$CI_COMMIT_TAG"
script:
[...]
- git add .
- git diff --cached --quiet || git commit -m "Update dbt submodule" // [!code focus]
# Pousser les modifications sans forcer la suppression
- git push origin dagster_submodule // [!code focus]
# Cette étape publie un artefact pour la documentation DBT.
pages:
stage: dbt_docs
only:
- main
script:
[...]
- dbt docs generate // [!code focus]👀 Automatiser l'observabilité
L'observabilité de notre plateforme de données est un aspect clé de la mise en œuvre d'une Plateforme de Données. Elle nous permet de surveiller la santé de nos systèmes (1) et de nos pipelines de données (2), de détecter les problèmes rapidement et d'assurer la qualité de nos données (3).
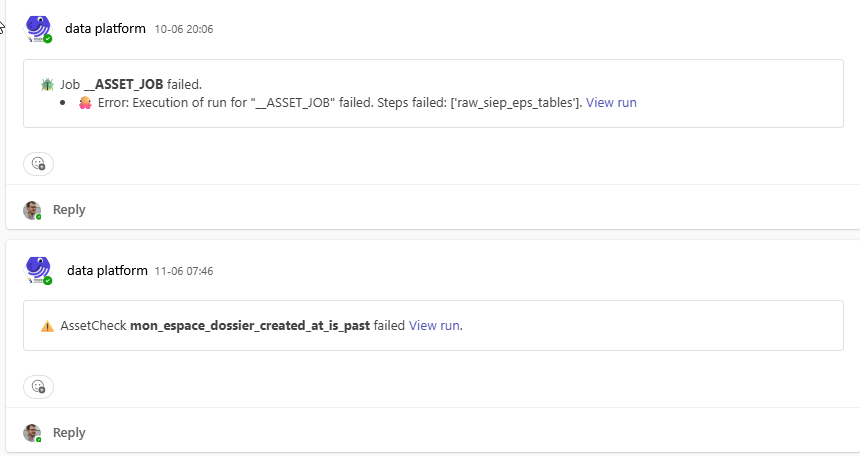
Panopticon
Observabilité de notre pile (conteneurs)
Pour l'observabilité de nos systèmes, nous utilisons Kibana et Dozzle pour surveiller les journaux et les métriques de notre plateforme de données.
Observabilité de nos pipelines de données
Comme un panopticon ou un hub d'observabilité centralisé, nous utilisons principalement un canal MS Teams (accessible par toutes les parties prenantes) pour centraliser l'observabilité de notre plateforme de données en un seul endroit. Certaines notifications personnalisées sont également envoyées via NTFY et Email pour des événements ou alertes spécifiques.
Observabilité de nos données
Pour l'observabilité de nos données, nous utilisons les fonctionnalités intégrées de Dagster pour vérifier la qualité de nos données. Dagster fournit un ensemble de fonctionnalités d'observabilité (personnalisées ou intégrées) qui nous permettent de surveiller la santé de nos pipelines de données et de détecter les problèmes rapidement.
Même sans écrire de vérifications personnalisées, l'interface utilisateur de Dagster nous permet de surveiller la qualité de nos données. Voici comment nous avons trouvé un problème de qualité dans l'un de nos pipelines de données :
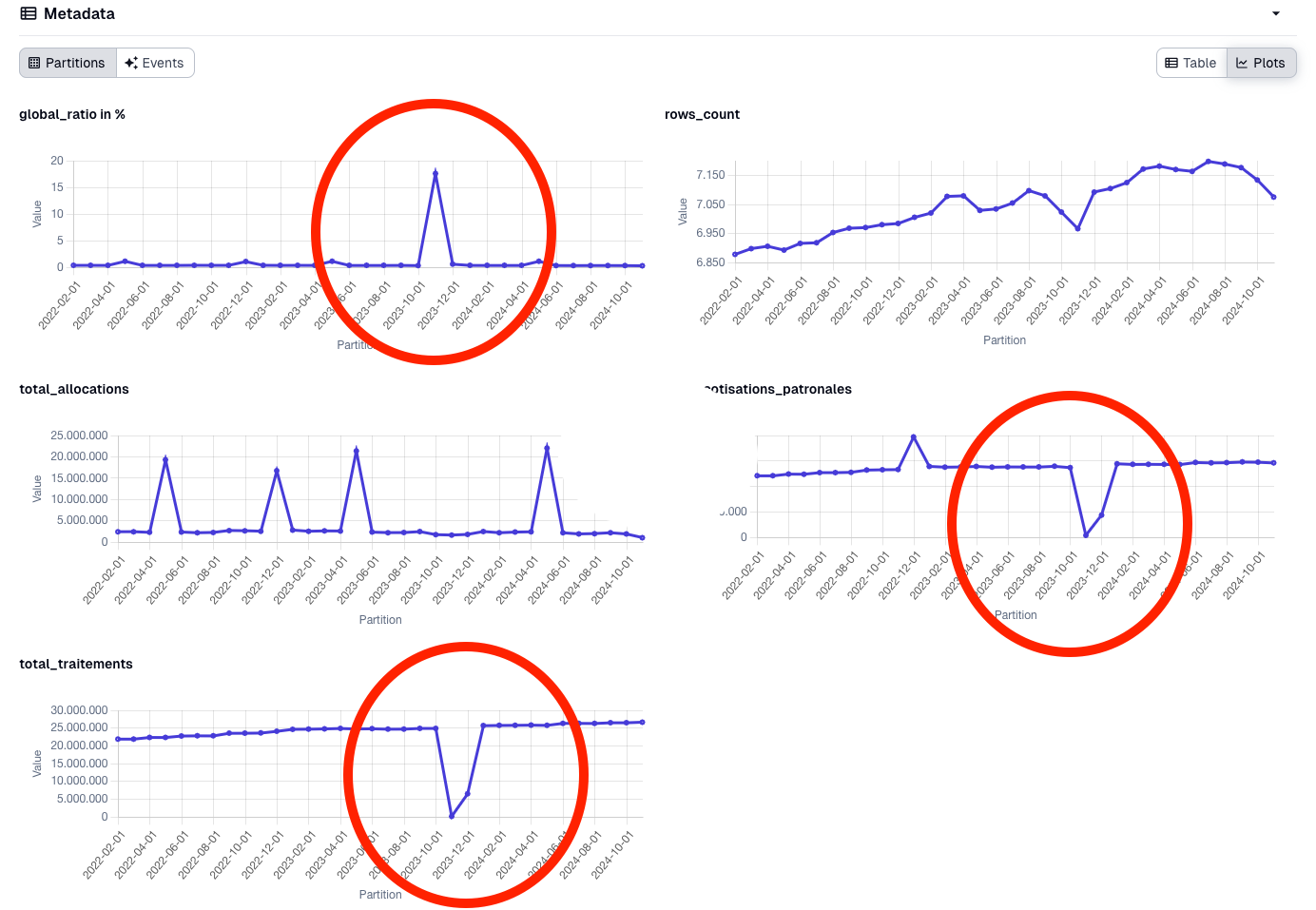
Comment la fonctionnalité d'observabilité nous a aidés à détecter des problèmes de qualité
Dans cet article, nous avons exploré comment automatiser le déploiement de pipelines de données dans une organisation polycéphale comme la FWB. Nous avons vu comment utiliser Dagster comme orchestrateur, dbt-core pour les transformations de données, et GitLab CI/CD pour automatiser le processus de déploiement.
Nous avons également discuté de l'importance de la modularité et de la réutilisabilité des composants pour abaisser la barrière technique pour les analystes de données et les gestionnaires de données. En automatisant le processus de déploiement, nous pouvons nous assurer que chaque commit est testé et validé avant d'être déployé en production, ce qui encourage la participation des analystes de données et des gestionnaires de données dans le développement de pipelines de données.
Mais comme indiqué dans l'introduction, le niveau de participation est inversement proportionnel à la barrière technique. Plus la configuration est complexe, moins les analystes de données et les gestionnaires de données sont susceptibles de participer au développement de pipelines de données.
Dans le prochain article, nous explorerons comment abaisser encore davantage la barrière technique en fournissant des ressources conviviales pour que les professionnels des données interagissent avec la plateforme de données. Nous discuterons également de la façon d'améliorer la littératie des données parmi les analystes de données et les gestionnaires de données pour les encourager à participer au développement de pipelines de données.