Appearance

Résumé exécutif : Dans une organisation polycéphale, la Gouvernance des Données est un défi complexe. Cet article explore la mise en œuvre d'une Plateforme de Données basée sur Dagster pour la Fédération Wallonie-Bruxelles (FWB). Il met en évidence l'importance de l'automatisation, de la modularité et de la réutilisabilité des composants pour abaisser la barrière technique et améliorer la littératie des données parmi les analystes de données et les gestionnaires de données.
Les opinions exprimées sur ce site web sont les miennes et ne reflètent pas nécessairement celles de mon employeur.
Table des matières
Après les deux premiers articles de cette série, qui se concentraient sur l'architecture de notre plateforme de données et l'automatisation de nos pipelines de données, cet article discutera de la façon dont nous pouvons baisser la barrière technique pour nos utilisateurs et améliorer leur littératie des données.
Il y a deux aspects principaux à cela :
- Réduire la complexité de notre plateforme de données en fournissant des ressources et des composants communs qui peuvent être réutilisés par tous les analystes de données et les gestionnaires de données.
- Améliorer la littératie des données de nos utilisateurs en les formant, en écrivant de la documentation, en les accompagnant dans leurs premiers pas, et en leur fournissant les outils nécessaires pour comprendre et utiliser la plateforme de données.
🧑💻 Réutilisabilité du code
Sans surprise, Dagster fournit deux concepts principaux pour aider à la réutilisabilité du code : les ressources et les composants.
- Les ressources sont utilisées pour se connecter à des systèmes externes (bases de données, API, etc.), pour fournir des fonctionnalités partagées (comme la journalisation, la surveillance, etc.), ou pour encapsuler une logique commune qui peut être réutilisée dans plusieurs jobs ou pipelines.
- Les composants (encore assez nouveaux) sont utilisés pour définir des morceaux de code réutilisables qui peuvent être invoqués avec une simple configuration de fichier
YAML. Les composants peuvent être utilisés pour encapsuler des tâches courantes, telles que les transformations de données, le chargement de données, la planification, etc.
Les deux concepts sont étroitement liés, car les ressources sont souvent utilisées dans les composants pour se connecter à des systèmes externes.
Puisque notre Plateforme de Données exploite plusieurs emplacements de code, et parce que nous voulons faciliter l'intégration de nouveaux ingénieurs de données, nous avons dû construire une bibliothèque Python commune qui contient toutes les ressources, composants et bibliothèques personnalisées (utils) nécessaires pour se connecter à nos sources de données. Nous avons appelé cette bibliothèque dagster-cfwb.
Implémenter une bibliothèque commune
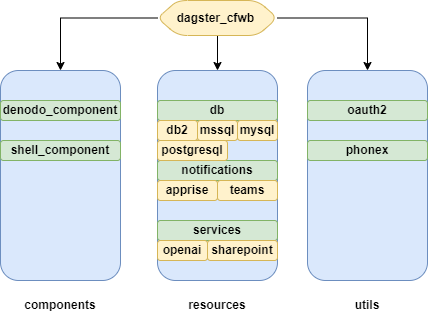
Notre package dagster-cfwb contient toutes les ressources Dagster nécessaires pour se connecter à nos sources de données. Cette bibliothèque est utilisée par la plupart des jobs et pipelines de notre plateforme de données. Elle inclut des ressources pour se connecter à diverses bases de données (PostgreSQL, MSSQL, MySQL, DB2, ...), des API (Denodo, API personnalisées, OAuth2, ...), et d'autres sources de données (lakehouse, FTP, NFS, ...). Elle inclut également des composants personnalisés qui peuvent être utilisés pour effectuer des tâches courantes, telles que l'importation de données depuis Denodo, le stockage dans le lakehouse de données, et le reporting de métadonnées.
Cette bibliothèque est également largement documentée (directement visible dans l'interface utilisateur de Dagster), versionnée, et testée avec des tests unitaires/d'intégration pendant notre pipeline GitLab CI/CD.
Pour illustrer cela, examinons les ressources AzureAdlsResource et PostgreSQLResource que nous avons implémentées dans la bibliothèque dagster-cfwb. Ces ressources sont utilisées pour se connecter à un Azure Data Lake Storage (ADLS) et une base de données PostgreSQL, respectivement.
python
from dagster_cfwb.resources.lakehouse.azure_adls_resource import AzureAdlsResource // [!code focus]
from dagster_cfwb.resources.db.postgresql_resource import PostgreSQLResource // [!code focus]
@asset()
def gld_example( // [!code focus]
context,
azure_adls: AzureAdlsResource, // [!code focus]
postgresql: PostgreSQLResource // [!code focus]
):
df = azure_adls.query_blob_storage("FROM 'azure://code_location/stg/example.parquet'") // [!code focus]
postgresql.copy_from_df(df, "example") // [!code focus]
return MaterializeResult(
metadata={
"dagster/row_count": df.shape[0],
"num_columns": df.shape[1],
"dashboard_url": MetadataValue.url(
"https://vizu.intranet.fwb.be/example_dashboard"
),
"documentation_url": MetadataValue.url(
"https://docs.intranet.fwb.be/example_documentation"
),
},
)Comme vous pouvez le voir, les ressources AzureAdlsResource et PostgreSQLResource sont utilisées pour se connecter au Azure Data Lake Storage et à la base de données PostgreSQL, respectivement. L'asset gld_example utilise ces ressources pour interroger des données depuis le Azure Data Lake Storage et les copier dans la base de données PostgreSQL. Toute la logique est encapsulée dans la bibliothèque dagster-cfwb, ce qui rend très facile la réutilisation de ce code.
Wiki et documentation
Pour abaisser davantage la barrière technique, nous maintenons un Wiki qui fournit de la documentation sur la façon d'utiliser la bibliothèque dagster-cfwb, comment écrire des jobs et pipelines Dagster, et comment utiliser la plateforme de données. Nous documentons également certaines bonnes pratiques, des normes de codage, des processus de déploiement et fournissons des exemples de la façon d'utiliser les ressources et composants dans la bibliothèque dagster-cfwb.
Utiliser les LLM pour aider les utilisateurs
Pour abaisser davantage la barrière technique, nous explorons actuellement l'utilisation de Large Language Models (LLMs) via un serveur MCP dédié pour aider les utilisateurs à écrire leurs propres jobs et pipelines Dagster. Cela permettra à nos professionnels de la donnée de se concentrer sur la logique métier de leurs pipelines de données, plutôt que sur les détails techniques de la façon de se connecter aux sources de données.
📖 Améliorer la littératie des données
Comme indiqué dans l'introduction, dans notre organisation, très peu de personnes sont formées à la gestion des données et à la programmation. Pour surmonter ce défi, nous communiquons beaucoup sur notre plateforme de données, nous formons nos utilisateurs, et nous leur fournissons les outils nécessaires pour comprendre et utiliser la plateforme de données.
Communiquer sur la plateforme de données
Comme le montre l'image ci-dessous, nous essayons d'utiliser des images simples mais puissantes pour expliquer la plateforme de données et ses composants. Cela aide nos parties prenantes à comprendre la plateforme de données, et plus important encore, les avantages qu'elle apporte à l'organisation.

Former les utilisateurs
Nous offrons également des sessions de formation à nos utilisateurs pour les aider à comprendre la plateforme de données et comment l'utiliser. Ces sessions de formation sont adaptées au niveau d'expertise technique des utilisateurs et couvrent des sujets tels que SQL, Python, Git, Docker, Lakehouse, Modélisation de données, Visualisation de données, etc.


Construire une communauté pour partager les connaissances
Enfin et surtout, nous essayons de construire une communauté de pratique pour partager les connaissances et les bonnes pratiques. Nous l'appelons "Communauté des intendants de données" (Community of Data Stewards). Cette communauté est ouverte à tous les professionnels de la donnée de l'organisation, quel que soit leur niveau d'expertise technique.
Nous organisons des réunions régulières pour partager des expériences et nous entraider face aux défis que nous rencontrons. Cela aide à créer une culture de littératie des données et encourage éventuellement les utilisateurs à participer au développement de pipelines de données.
📝 Conclusion
Dans cette série d'articles, nous avons exploré la mise en œuvre d'une Plateforme de Données basée sur Dagster pour la Fédération Wallonie-Bruxelles (FWB).
Nous avons discuté de l'architecture de notre plateforme de données, de l'automatisation de nos pipelines de données, et de la façon dont nous abaissons la barrière technique pour nos utilisateurs et améliorons leur littératie des données. Nous avons apprécié construire cette plateforme de données et nous espérons que cette série d'articles vous aidera à construire votre propre plateforme de données avec des outils Open Source.
Nous espérons également que cette série d'articles vous aidera à comprendre les défis de la construction d'une plateforme de données dans une organisation polycéphale et comment les surmonter.