Appearance

Executive summary: In a polycephalous organization, Data Governance is a complex challenge. This article explores the implementation of a Data Platform based on Dagster for the Fédération Wallonie-Bruxelles (FWB). It highlights the importance of automation, modularity, and component reusability to lower the technical barrier and improve data literacy among data analysts and data stewards.
The views expressed on this website are my own and do not necessarily reflect the views of my employer.
Table of contents
After the first two articles in this series, which focused on the architecture of our data platform and the automation of our data pipelines, this article will discuss how we lower the technical barrier for our users and improve their data literacy.
There are two main aspects to this:
- Reduce the complexity of our data platform by providing common resources and components that can be reused by all data analysts and data stewards.
- Level up the data literacy of our users by training them, writing documentation, accompanying them in their first steps, and providing them with the necessary tools to understand and use the data platform.
🧑💻 Code reusability
Without any surprise, Dagster provides two main concepts to help code reusability: resources and components.
- Resources are used to connect to external systems (databases, APIs, etc.), to provide shared functionality (like logging, monitoring, etc.), or to encapsulate common logic that can be reused across multiple jobs or pipelines.
- Components (still kind of new) are used to define reusable pieces of code that can be invoke with a simple
YAMLconfig file configuration. Components can be used to encapsulate common tasks, such as data transformations, data loading, sheduling, etc.
The two concepts are closely related, as resources are often used in components to connect to external systems.
Since our Data Platform leverages multiple code locations, and because we want to facilitate the onboarding of new data engineers, we needed to build a common Python library that contains all the resources, components, and custom libraries (utils) required to connect to our data sources. We called this library dagster-cfwb.
Implement a common library
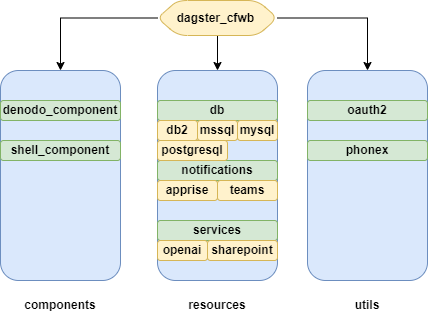
Our dagster-cfwb package contains all the Dagster resources needed to connect to our data sources. This library is used by most jobs and pipelines in our data platform. It includes resources for connecting to various databases (PostgreSQL, MSSQL, MySQL, DB2, ...), APIs (Denodo, custom APIs, OAuth2, ...), and other data sources (lakehouse, FTP, NFS, ...). It also includes custom components that can be used to perform common tasks, such as importing data from Denodo, storing to the data lakehouse, and reporting metadata.
This library is also extensively documented (directly visible in the Dagster UI), versioned, and tested with unit/integration tests during our GitLab CI/CD pipeline.
To illustrate this, let's take a look at the AzureAdlsResource and PostgreSQLResource resources that we implemented in the dagster-cfwb library. These resources are used to connect to an Azure Data Lake Storage (ADLS) and a PostgreSQL database, respectively.
python
from dagster_cfwb.resources.lakehouse.azure_adls_resource import AzureAdlsResource // [!code focus]
from dagster_cfwb.resources.db.postgresql_resource import PostgreSQLResource // [!code focus]
@asset()
def gld_example( // [!code focus]
context,
azure_adls: AzureAdlsResource, // [!code focus]
postgresql: PostgreSQLResource // [!code focus]
):
df = azure_adls.query_blob_storage("FROM 'azure://code_location/stg/example.parquet'") // [!code focus]
postgresql.copy_from_df(df, "example") // [!code focus]
return MaterializeResult(
metadata={
"dagster/row_count": df.shape[0],
"num_columns": df.shape[1],
"dashboard_url": MetadataValue.url(
"https://vizu.intranet.fwb.be/example_dashboard"
),
"documentation_url": MetadataValue.url(
"https://docs.intranet.fwb.be/example_documentation"
),
},
)As you can see, the AzureAdlsResource and PostgreSQLResource resources are used to connect to the Azure Data Lake Storage and PostgreSQL database, respectively. The gld_example asset uses these resources to query data from the Azure Data Lake Storage and copy it to the PostgreSQL database. All the logic is encapsulated in the dagster-cfwb library, which makes it very easy to reuse this code.
Wiki and documentation
To further lower the technical barrier, we maintain a Wiki that provides documentation on how to use the dagster-cfwb library, how to write Dagster jobs and pipelines, and how to use the data platform. We also document some best practices, coding standards, deployment processes and provide examples of how to use the resources and components in the dagster-cfwb library.
Use LLM to help users
To further lower the technical barrier, we are currenlty exploring the use of Large Language Models (LLMs) through a dedicated MCP server to help users write their own Dagster jobs and pipelines. This will allow our data professionals to focus on the business logic of their data pipelines, rather than the technical details of how to connect to the data sources.
📖 Level up the data literacy
As stated in the introduction, in our organisation very few people are trained in data management and programming. To overcome this challenge, we communicate a lot about our data platform, we train our users, and we provide them with the necessary tools to understand and use the data platform.
Communicate about the data platform
As shown in the image below, we try to use simple yet powerful images to explain the data platform and its components. This helps our stakeholders understand the data platform, and more importantly, the benefits it brings to the organization.

Train the users
We also provide training sessions to our users to help them understand the data platform and how to use it. These training sessions are tailored to the level of technical expertise of the users and cover topics such as SQL, Python, Git, Docker, Lakehouse, Data modeling, Data visualization, etc.


Build a community to share knowledge
Last but not least, we try to build a community of practice to share knowledge and best practices. We call it "Communauté des intendants de données" (Community of Data Stewards). This community is open to all data professionals in the organization, regardless of their level of technical expertise.
We organise regular meetings to share experiences and help each other with the challenges we face. This helps to create a culture of data literacy and enventually encourages users to participate in the development of data pipelines.
📝 Conclusion
In this series of articles, we have explored the implementation of a Data Platform based on Dagster for the Fédération Wallonie-Bruxelles (FWB).
We have discussed the architecture of our data platform, the automation of our data pipelines, and how we lower the technical barrier for our users and improve their data literacy. We enjoyed building this data platform and we hope that this series of articles will help you to build your own data platform with Open Source tools.
We also hope that this series of articles will help you to understand the challenges of building a data platform in a polycephalous organization and how to overcome them.