Appearance

Executive summary: In Belgium, a collaborative effort between regional and federal authorities has led to the creation of a unified service that aggregates all Belgian addresses into a comprehensive dataset. This dataset is called BeStAddress.
Address lookup - Sourcing (2)
Introduction
In the previous post, we have analyzed the data model of the BeStAddress dataset. In this post, we will focus on building a unified table that aggregates all the data from the different regions of Belgium. It will be the first step to build an address lookup service.
Sources
The BeStAddress dataset is composed of different tables. For facilitating the exploration, we used the CSV files provided by the BeStAddress service. XML and Web service is also available -- however XML is harder to parse and the API needs to register and get an API key.
The data is split into three regions:
- BeVlg: Flanders
- BeBru: Brussels
- BeWal: Wallonia
As shown in the previous article, the data model is similar for the three regions -- but the model is not very obvious. For this reason, we will create a unified table that will be easier to work with. The concept of One Big Table designs are amazing for performance in analytics (expecially with OLAP system) but can be a nightmare for data analysis and data quality.
Downloading the data
We will use Dagster to download the data and DuckDB create the big table. Using Dagster will allow us to define a pipeline that will download the data from the different regions and store it in a local database. It will be easy to run the pipeline again if we need to update the data and we can also use Dagster to monitor the data quality.
Defining the asset in Dagster
python
specs = []
for table in bestAddress_zones:
output_name = "raw_bestAddress_" + table
specs.append(AssetSpec(key=output_name, kinds={"duckdb", 'azure', 'pandas'}))
@multi_asset(
group_name="raw",
specs=specs,
can_subset=False,
description="The complete BestAddress files loaded into a DuckDB",
)
def raw_bestaddress_tables(
context, duckdb_bestAddress: DuckDBResource
) -> MaterializeResult:
for table_name in bestAddress_zones:
url = (
"https://opendata.bosa.be/download/best/openaddress-" + table_name + ".zip"
)
r = requests.get(url)
z = zipfile.ZipFile(io.BytesIO(r.content))
extract_location = "/tmp/"
z.extractall(extract_location)
df = pd.read_csv(
extract_location + "openaddress-" + table_name + ".csv", dtype=str
)
asset_name = "raw_bestAddress_" + table_name
...
with duckdb_bestAddress.get_connection() as conn:
conn.execute(f"CREATE OR REPLACE TABLE {table_name} AS SELECT * FROM df")
...Creating the unified table
Once the data is downloaded, we can create a unified table that will aggregate the data from the different regions. We will use the UNION ALL operator to merge the data from the different regions. We will also create a unique identifier of fixed length for each address by concatenating the municipality_id, street_id, and address_id. This will allow us to easily have a single identifier for each address (will be handy for the address lookup service).
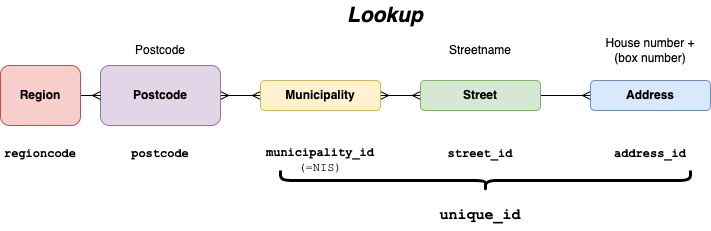
best address
We will also create some custom columns that will be useful. For example, we will create a default_streetname column that will contain the street name in the three languages. We will also create a formatted_address1 and formatted_address2 column that will contain the formatted address with the street name and the house number. Finally, we will rename latitude and longitude column that will contain the coordinates of the address.
sql
CREATE OR REPLACE TABLE bestAddress AS
WITH raw_data AS (
SELECT * FROM bevlg -- in practice we can also use the read_csv() function
UNION ALL
SELECT * FROM bebru
UNION ALL
SELECT * FROM bewal
),
prepared_data AS (
SELECT
concat_ws(
'-',
municipality_id,
lpad(cast(street_id as varchar), 8, '0'),
lpad(cast(address_id as varchar), 8, '0')
)
AS unique_id,
status,
streetname_fr,
streetname_de,
streetname_nl,
concat_ws(' / ', streetname_fr, streetname_de, streetname_nl)
AS default_streetname,
house_number,
box_number,
concat_ws(' / ', house_number, box_number)
AS full_house_number,
postcode,
municipality_name_fr,
municipality_name_de,
municipality_name_nl,
concat_ws(' / ', municipality_name_fr, municipality_name_de, municipality_name_nl)
AS default_municipality_name,
concat_ws(' / ', postname_fr, postname_nl)
AS default_postname,
postname_fr,
postname_nl,
concat(
concat_ws(' / ', streetname_fr, streetname_de, streetname_nl), ' ',
concat_ws('/', house_number, box_number)
) AS formatted_address1,
concat_ws(' ', postcode,
coalesce(
concat_ws(' / ', postname_fr, postname_nl),
concat_ws(' / ', municipality_name_fr, municipality_name_de, municipality_name_nl)
)
) AS formatted_address2,
region_code,
cast(municipality_id AS integer)
AS municipality_id,
cast(street_id AS integer)
AS street_id,
cast(address_id AS integer)
AS address_id,
cast("EPSG:4326_lat" AS FLOAT)
AS latitude,
cast("EPSG:4326_lon" AS FLOAT)
AS longitude
FROM raw_data
)
SELECT * FROM prepared_data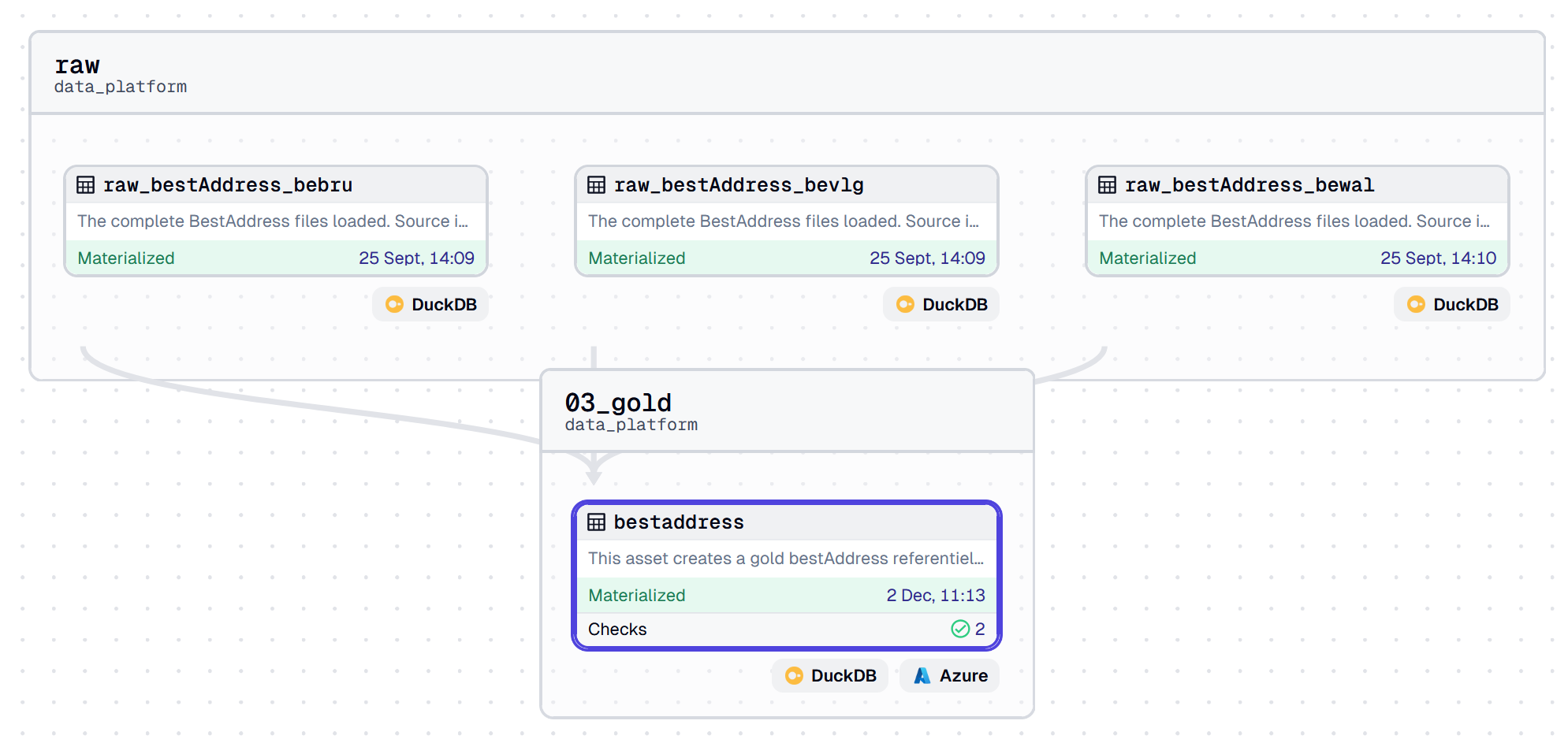
best address pipeline in Dagster
Next steps
In the next post, we will focus on creating an address lookup service (FastAPI) that will use the unified table we have created.