Appearance

Executive summary: In Belgium, a collaborative effort between regional and federal authorities has led to the creation of a unified service that aggregates all Belgian addresses into a comprehensive dataset. This dataset is called BeStAddress.
Address lookup - Analysis (1)
Introduction
This article outlines an experiment conducted by the Data Office of the Ministère de la Fédération Wallonie-Bruxelles aimed at leveraging existing address datasets more effectively.
The primary objective is to optimize the process of looking up addresses by postal codes, street names, and house numbers within these datasets, and eventually matching them with the BeStAddress dataset.
In Belgium, a collaborative initiative led by BOSA, in partnership with regional and federal authorities, resulted in the creation of a unified service that consolidates all Belgian addresses into a single, comprehensive dataset known as BeStAddress.
Quick overview of BeStAddress
At first glance, the dataset appears to be quite comprehensive, providing a wealth of information on addresses in Belgium. Key data points include:
- Municipality names in French, Dutch, and German
- Postnames in French, Dutch, and German: In Belgium, postnames are used to identify specific zones within a municipality or across parts of one or several municipalities (further details on this will be provided later).
- Street names in French, Dutch, and German (often available in only one language depending on the region)
- Postcodes
- House numbers
- Box numbers
Example of a single record (as JSON):
json
{
"status": "current",
"streetname_fr": "Rue de la Loi",
"streetname_de": null,
"streetname_nl": "Wetstraat",
"house_number": "16",
"box_number": null,
"postcode": "1000",
"municipality_name_fr": "Bruxelles",
"municipality_name_de": null,
"municipality_name_nl": "Brussel",
"postname_fr": "Bruxelles (Centre)",
"postname_nl": "Brussel (Centrum)",
"region_code": "BE-BRU",
"municipality_id": 21004,
"street_id": 1679,
"address_id": 210225,
"EPSG:4326_lat": 50.84616,
"EPSG:4326_lon": 4.36653,
"EPSG:31370_x": 148303.0,
"EPSG:31370_y": 169017.0
}Summarize the datasets
Based on the export from BOSA website of the dataset in flat format (gzipped CSV) of the 2024-09-23, the dataset contains 6 608 518 records of status = current.
Here are summaries of each column in each dataset:
- Brussels (Bruxelles) dataset summary
- Flanders (Vlaanderen) dataset summary
- Wallonia (Wallonie) dataset summary
As we can see, the dataset contains a lot of fields. It is also multilingual, which seems obivious for an official dataset in Belgium (where French, Dutch and German are the official languages). It also contains some specific identifiers such as:
municipality_id(unique identifier for each municipality is equal to the NIS codes)street_idaddress_id
Checking uniqueness of the identifiers
The first step is to check the uniqueness of the identifiers in the dataset. We will check if the street_id, municipality_id, and address_id are unique.
Let's write a query that will count per region the number of unique street_id, municipality_id, and address_id and the total number of records. If the sum of the unique counts is equal to the total number of records, it means that the identifiers are unique in the dataset.
sql
SELECT 'BE-BRU' AS region_code,
COUNT(DISTINCT municipality_id) AS municipality_id_count,
COUNT(DISTINCT street_id) AS street_id_count,
COUNT(DISTINCT address_id) AS address_id_count
FROM bestAddress_BRU
WHERE status = 'current'
UNION ALL
SELECT 'BE-WAL' AS region_code,
COUNT(DISTINCT municipality_id) AS municipality_id_count,
COUNT(DISTINCT street_id) AS street_id_count,
COUNT(DISTINCT address_id) AS address_id_count
FROM bestAddress_WAL
WHERE status = 'current'
UNION ALL
SELECT 'BE-VLG' AS region_code,
COUNT(DISTINCT municipality_id) AS municipality_id_count,
COUNT(DISTINCT street_id) AS street_id_count,
COUNT(DISTINCT address_id) AS address_id_count
FROM bestAddress_VLG
WHERE status = 'current'
UNION ALL
SELECT 'TOTAL' AS region_code,
COUNT(DISTINCT municipality_id) AS municipality_id_count,
COUNT(DISTINCT street_id) AS street_id_count,
COUNT(DISTINCT address_id) AS address_id_count
FROM bestAddress;Results
| region_code | municipality_id_count | street_id_count | address_id_count |
|---|---|---|---|
| BE-BRU | 19 | 5095 | 790713 |
| BE-WAL | 262 | 57707 | 1983442 |
| BE-VLG | 300 | 80354 | 3834363 |
| TOTAL | 581 | 138457 | 4203561 |
| SUM = TOTAL | ok! ✅ | nope ⛔ | nope ⛔ |
- The
municipality_idis unique in the dataset, which is mean that a municipality is unique in each region and is not shared between regions. This is expected as themunicipality_idis equal to the NIS codes. The municipalities have a political and administrative meaning and are unique in each region. - The
street_idshows that a street can be shared between multiple municipalities. This is not surprising as some streets can cross multiple municipalities. - The
address_idis not unique throughout the three datasets, but it is probably unique in each dataset.
Let's check the uniqueness of the address_id in each dataset.
sql
SELECT 'BE-BRU' AS region_code,
COUNT(DISTINCT address_id) AS address_id_count,
COUNT(*) AS total_row_count
FROM bestAddress_BRU
WHERE status = 'current'
UNION ALL
SELECT 'BE-WAL' AS region_code,
COUNT(DISTINCT address_id) AS address_id_count,
COUNT(*) AS total_row_count
FROM bestAddress_WAL
WHERE status = 'current'
UNION ALL
SELECT 'BE-VLG' AS region_code,
COUNT(DISTINCT address_id) AS address_id_count,
COUNT(*) AS total_row_count
FROM bestAddress_VLG
WHERE status = 'current'
UNION ALL
SELECT 'TOTAL' AS region_code,
COUNT(DISTINCT address_id) AS address_id_count,
COUNT(*) AS total_row_count
FROM bestAddress;| region_code | address_id_count | total_row_count |
|---|---|---|
| BE-BRU | 790713 | 790713 |
| BE-WAL | 1983442 | 1983442 |
| BE-VLG | 3834363 | 3834363 |
| TOTAL | 4203561 | 6608518 |
Indeed the address_id is unique in each dataset but is not unique throughout the three datasets.
Understanding the data structure - Deep dive
At first glance, we could think from the variables that a postcode include 1 or more municipalities and each municipality include 1 or more streets.
The model could simply be something like this:
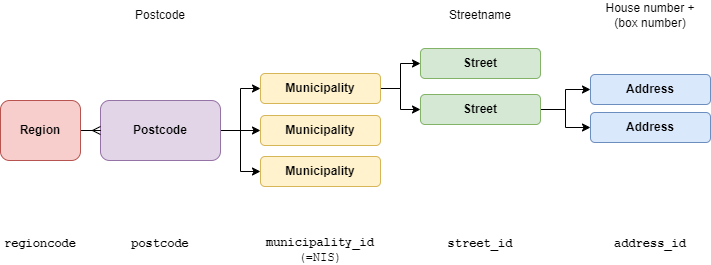
best address wrong model
Let's check the data to see if this is true.
In some cases, a street can be shared between 2 municipalities. This is the case for example of the street Rue de la Loi which is in postcodes ['1000', '1012', '1040','1045', '1049'] for status_code = 'BE-BRU'.
sql
SELECT
DISTINCT(postcode)
FROM bestAddress_bxl
WHERE 1=1
AND street_id = 1679
AND status = 'current'On the other hand, a municipality_id can belong to multiple postcodes.
sql
SELECT
DISTINCT(postcode)
FROM bestAddress_bxl
WHERE 1 = 1
AND municipality_id = 21004 -- Bruxelles
AND status = 'current'This will return 14 distincts postcodes: ['1047', '1010', '1045', '1030', '1070', '1000', '1020', '1012', '1130', '1040', '1050', '1120', '1007', '1049'].
In reverse, a postcode can have multiple municipality_id values.
sql
SELECT
DISTINCT(municipality_id)
FROM bestAddress_bxl
WHERE 1=1
AND postcode = '1050' -- Ixelles
AND status = 'current'This will return 3 distincts municipality_id: ['21009', '21013', '21004'].
Finally, a street with the same name, could have multiple street_id and municipality_id even within the same postcode. This is the case for example of the street Avenue Louise.
sql
SELECT
municipality_id,
street_id,
postcode
FROM bestAddress_BRU
WHERE 1 = 1
AND streetname_fr = 'Avenue Louise'
AND status = 'current'
GROUP BY all;| municipality_id | street_id | postcode |
|---|---|---|
| 21004 | 1858 | 1050 |
| 21009 | 3919 | 1050 |
| 21013 | 751 | 1060 |
Global overview
To better understand the relationships between the different entities in the dataset, we can perform some checks to see if there are any many-to-many relationships between the entities.
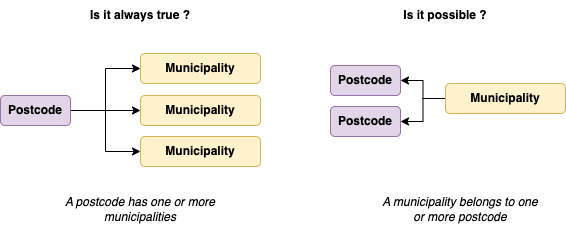
Let's check the data
1. Checking if a postcode belongs to multiple municipality_id values
To check if a postcode is associated with multiple municipality_id values, you can group by the postcode and count distinct municipality_id values. If a postcode has more than 1 unique municipality_id, it means that the postcode is associated with multiple municipalities.
sql
SELECT postcode,
COUNT(DISTINCT municipality_id) AS municipality_count
FROM bestAddress
GROUP BY postcode
HAVING COUNT(DISTINCT municipality_id) > 1;| postcode | municipality_count |
|---|---|
| 4910 | 2 |
| 1050 | 3 |
| 1030 | 2 |
| 1070 | 2 |
| 1040 | 2 |
This query will return all postcodes that are associated with more than one municipality_id. We only get 5 postcodes that are associated with multiple municipalities.
2. Checking if a municipality_id belongs to multiple postcode values
Similarly, to check if a municipality_id is associated with multiple postcode values, group by municipality_id and count distinct postcode values. If a municipality_id has more than 1 unique postcode, it means that the municipality_id is associated with multiple postcodes.
sql
SELECT municipality_id,
COUNT(DISTINCT postcode) AS postcode_count
FROM bestAddress
GROUP BY municipality_id
HAVING COUNT(DISTINCT postcode) > 1;| municipality_id | postcode_count |
|---|---|
| 73042 | 2 |
| 11002 | 14 |
| ... | ... |
This query will return all municipality_id that are associated with more than one postcode. We have a 221 municipality_id that are associated with multiple postcodes. Only the first ones are shown here.
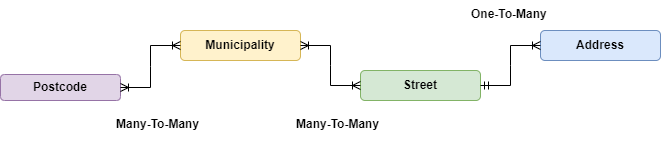
The relationship between postcodes and municipalities is then a many-to-many relationship.
3. Checking if a street_id belongs to multiple municipality_id values
To check if a street is associated with multiple municipalities, you can group by the street_id and count distinct municipality_id values. If a street has more than 1 unique municipality_id, it means that the street is associated with multiple municipalities.
sql
SELECT concat_ws('-',region_code, street_id) AS unique_street,
COUNT(DISTINCT municipality_id) AS municipality_count
FROM bestAddress
GROUP BY concat_ws('-',region_code, street_id) AS unique_street
HAVING COUNT(DISTINCT municipality_id) > 1;This query will return all street_ids in the same region that are associated with more than one municipality_id. We have 15 street_id that are associated with more than one municipality_id.
4. Checking if a street_id can have multiple postname_* values
sql
SELECT
concat_ws('-',municipality_id, street_id) AS unique_street,
COUNT(DISTINCT concat_ws(' / ', postname_fr, postname_nl)) AS postname_count
FROM bestAddress
GROUP BY all
HAVING COUNT(DISTINCT default_postname) > 1;This query will return all unique streets that are associated with more than one postname_* values. We have 3104 unique streets that are associated with more than one postname_* values.
Example of a street with multiple postnames:
sql
SELECT
DISTINCT(default_postname),
COUNT(address_id) AS address_count
FROM bestAddress
WHERE municipality_id = 25117 AND street_id = 7705267
GROUP BY all;| default_postname | address_count |
|---|---|
| Chastre | 32 |
| Villeroux | 1 |
We conclude that a street can be associated with multiple postnames.
Takeaways from the analysis
Let's check the data
- The
postcodecan be associated with multiplemunicipality_idvalues and amunicipality_idcan be associated with multiplepostcodevalues. The relationship between postcodes and municipalities is then a many-to-many relationship. - The
municipality_idis unique in the dataset, which is mean that a municipality is unique in each region and is not shared between regions. - The
address_idis unique in each dataset but is not unique throughout the three datasets. A sameaddress_idcan be found in multiple regions. - The
street_idshows that a street can be shared between multiple municipalities and that a municipality can have multiple streets. The relationship between streets and municipalities is then a many-to-many relationship. - Postname are not unique for a street. A single street can have multiple postnames. We will consider the
postname_*as an attribute of the address and not as a key.
Next steps
In the next article, we will explore build a Big Table model of the dataset to use it in a more efficient way for address lookup.
Next steps: Address lookup - Part 2 - Sourcing